🛠️ Application of TAPTRs in video editing and trajectory prediction.
🧬 What is TAPTR.
Inspired by recent visual prompt-based detection [1], we propose to convert Track Any Point (TAP) task to point-level visual prompt detection task. Building upon the recent advanced DEtection TRansformer (DETR) [2, 3, 4, 5], we propose our Track Any Point TRansformer (TAPTR).
[1] T-rex2: Towards Generic Object Detection via Text-visual Prompt Synergy. IDEA-Research. ECCV2024.
[2] DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR. IDEA-Research. ICLR2022.
[3] DN-DETR: Accelerate DETR Training by Introducing Query DeNoising. IDEA-Research. CVPR2022.
[4] DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection. IDEA-Research. ICLR2023.
[5] DINO-X: A Unified Vision Model for Open-World Object Detection and Understanding. IDEA-Research. ArXiv2024.
👣 From V1 to V3, a brief overview.
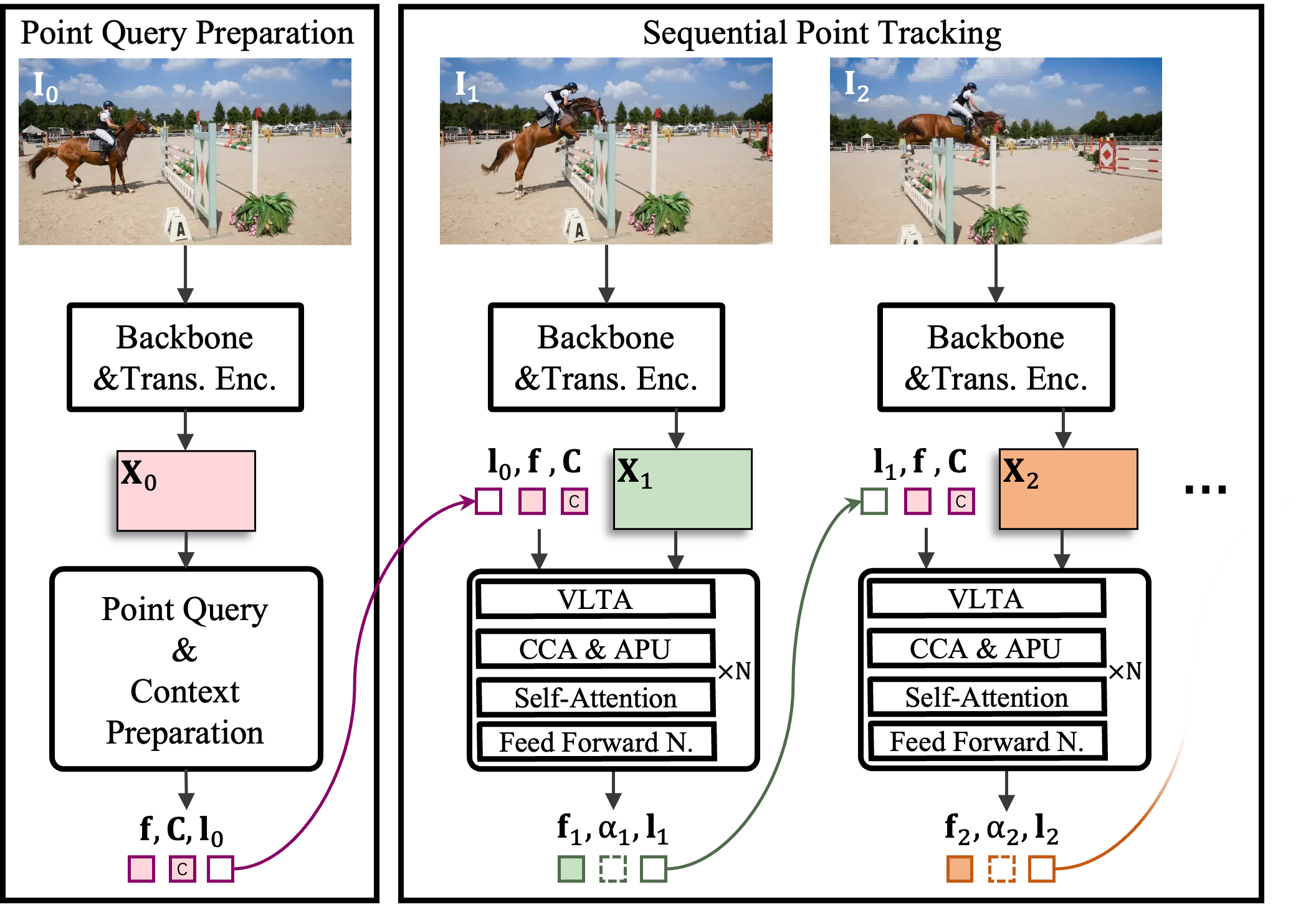
TAPTRv1 - Simple yet strong baseline.
TAPTRv1 first proposes to address TAP task from the perspective of detection. Instead of building upon the traditional optical flow methods, TAPTRv1 is also the first to propose adopting the more advanced DETR-like framework for the TAP task. Compared with previous methods, TAPTRv1 has a clearer and simpler definition of point query and better performance.
Although TAPTRv1 achieves SoTA performance with the DETR-like framework, TAPTRv1 still needs the source-consuming cost-volume to obtain its optimal performance.
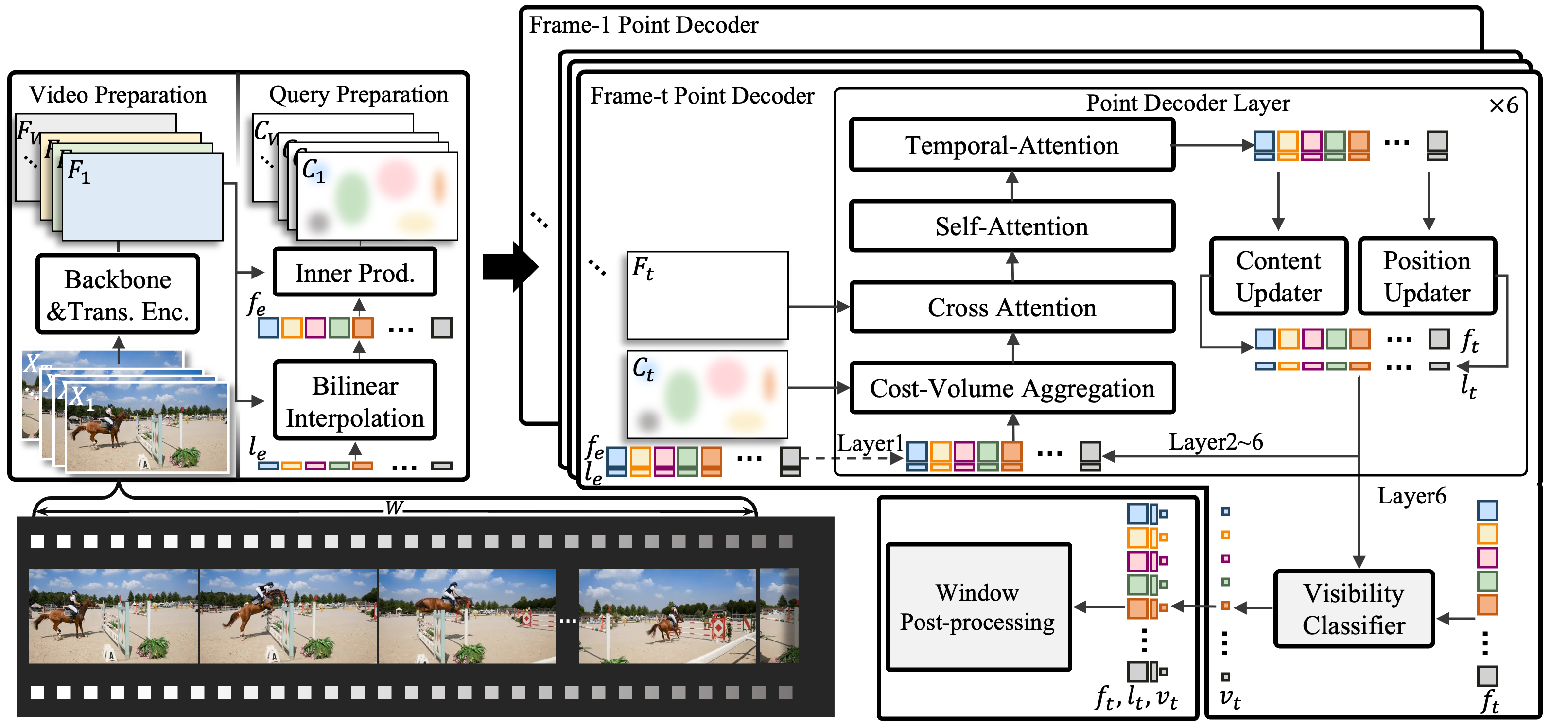
TAPTRv2 - Simpler and stronger.
TAPTRv2 finds that the reliance of cost-volume stems from the domain gap between training and evaluation data. The use of cost-volume in TAPTRv1 will also contaminate the point query. TAPTRv2 finds that the attention weights and cost-volume are essentially the same (attention weights in key-aware deformable cross attention can be regarded as sparse cost-volume). TAPTRv2 proposes the Attention-based Position Update (APU) to utilize this domain-agnostic information while preventing point queries from being contaminated. The elimination of cost-volume makes TAPTRv2 unifies the framework of both object-level and point-level perception.
Although TAPTRv2 achieves simpler framework and better performance, TAPTRv2’s performance in long videos is still not satisfying.
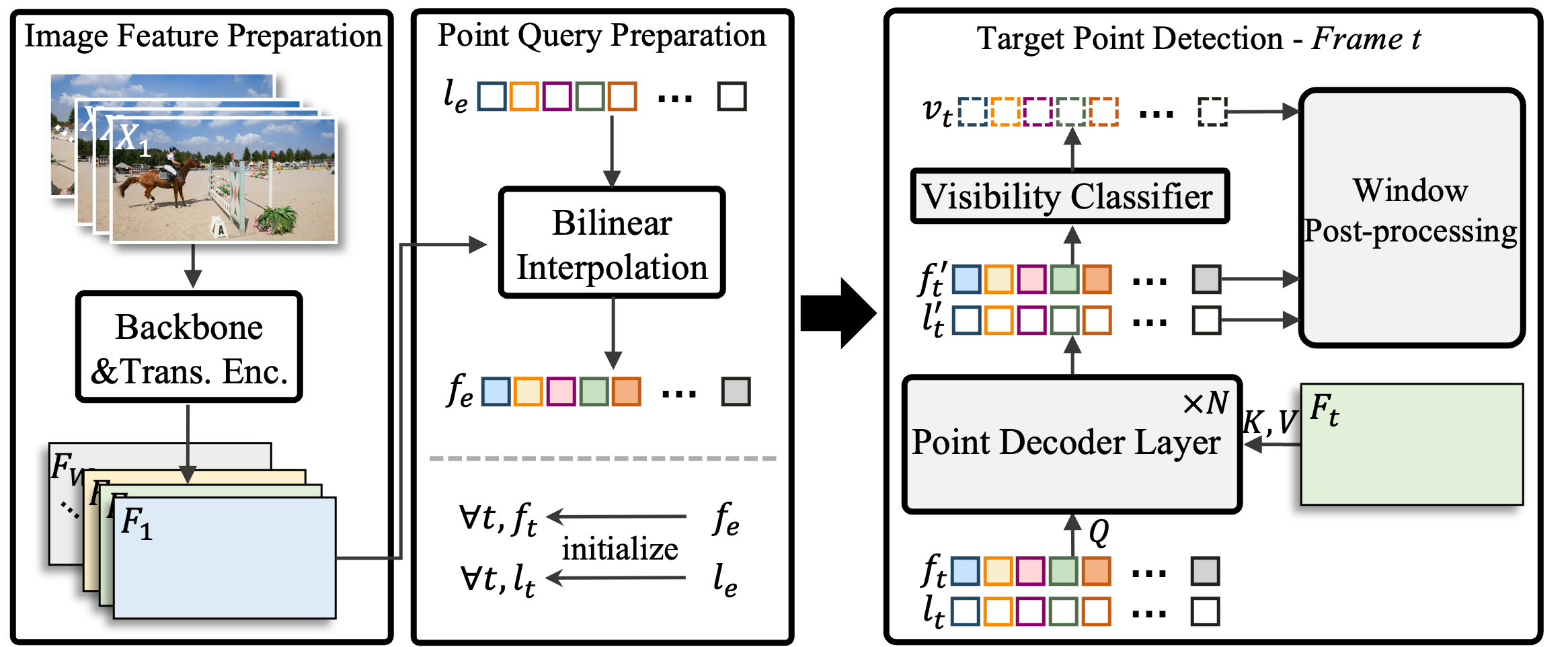
TAPTRv3 - Much stronger, especially on long-term tracking.
TAPTRv3 finds that the poor performance of TAPTRv2 on long videos is due to its shortage of feature querying in both spatial and temporal dimensions in long videos. For better temporal feature querying, instead of utilizing the RNN-like long-temporal modeling, TAPTRv3 extends the temporal attention from a small window to arbitrary length while considering the target tracking points' visibility, and proposes the Visibility-aware Long-Temporal Attention (VLTA). For better spatial feature querying, TAPTRv3 utilizes the spatial context to improve the quality of attention weights in cross attention, and proposes the Context-aware Cross Attention (CCA). To help TAPTRv3 reestablish tracking when a scene cut occurs with sudden large motion, which is quite prevalent in long-term videos, TAPTRv3 proposes to trigger global matching module to reset point queries' initial locations when a scene cut is detected. TAPTRv3 achieves SoTA performance on almost all TAP datasets, even when compared with methods trained on large-scale extra internal data, TAPTRv3 is still competitive.
💯 Performance
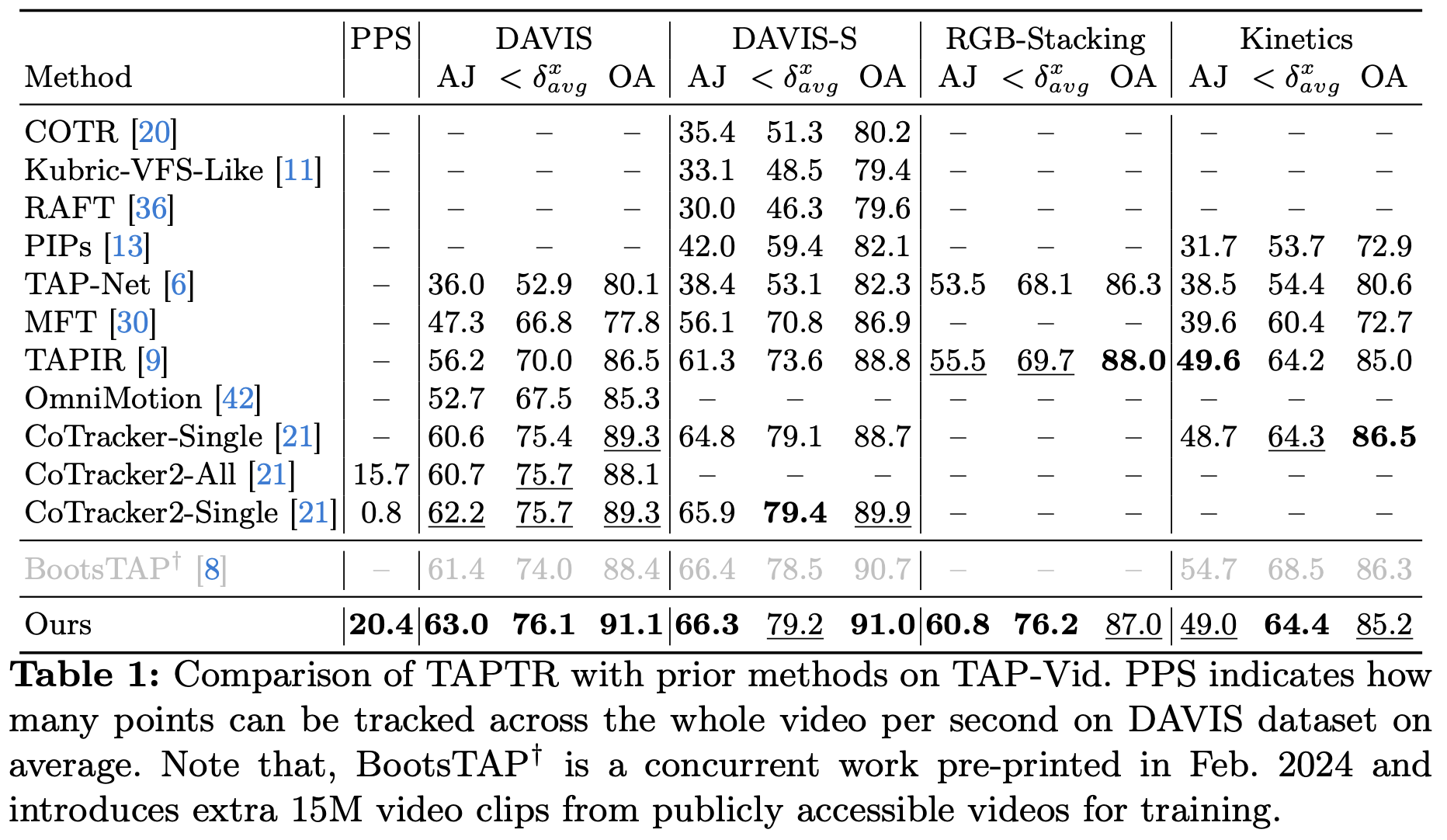
Through three versions of optimization, TAPTRv3 achieves state-of-the-art performance. Even when compared with methods trained on large-scale extra internal data (we only train TAPTRv3 on a small synthetic dataset, while BootsTAPIR and CoTracker3 are refined on their large-scale internal real-world dataset), TAPTRv3 is still competitive.
🗓 Future work and collaboration opportunities.
1. Extend TAPTR to Track Any Visual Prompt TRansformer (TAVTR).
2. Exploring the application of TAPTR in embodied AI scenarios.
If you have any interest in collaboration, feel free to contact us!
BibTeX
@inproceedings{li2024taptr,
title={{TAPTR: Tracking Any Point with Transformers as Detection}},
author={Li, Hongyang and Zhang, Hao and Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Lei},
booktitle={European Conference on Computer Vision},
pages={57--75},
year={2024},
organization={Springer}
}
@article{li2024taptrv2
title={{TAPTRv2: Attention-based Position Update Improves Tracking Any Point}},
author={Li, Hongyang and Zhang, Hao and Liu, Shilong and Zeng, Zhaoyang and Li, Feng and Ren, Tianhe and Li, Bohan and Zhang, Lei},
journal={Advances in Neural Information Processing Systems},
year={2024}
}
@article{Qu2024taptrv3,
title={{TAPTRv3: Spatial and Temporal Context Foster Robust Tracking of Any Point in Long Video}},
author={Qu, Jinyuan and Li, Hongyang and Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Zhang, Lei},
journal={arXiv preprint},
year={2024}
}